
در فرآیند آموزش یک شبکه عصبی، هدف اصلی این است که مدل یاد بگیرد خروجیهای دقیقتری تولید کند. اما مدل از کجا میفهمد که پیشبینیهایش خوب بوده یا بد؟ پاسخ این سؤال در «تابع هزینه» یا «تابع زیان» نهفته است.
تابع هزینه معیاری ریاضی است که میزان اختلاف بین خروجی پیشبینیشده مدل و مقدار واقعی را اندازهگیری میکند. هرچه مقدار این تابع کمتر باشد، یعنی مدل عملکرد بهتری دارد. فرآیند آموزش شبکههای عصبی در واقع تلاش برای کمینهسازی همین تابع هزینه با استفاده از الگوریتمهایی مانند Gradient Descent است.
در ادامه مهمترین توابع هزینه را بهصورت دقیق، مفهومی و کاربردی بررسی میکنیم.
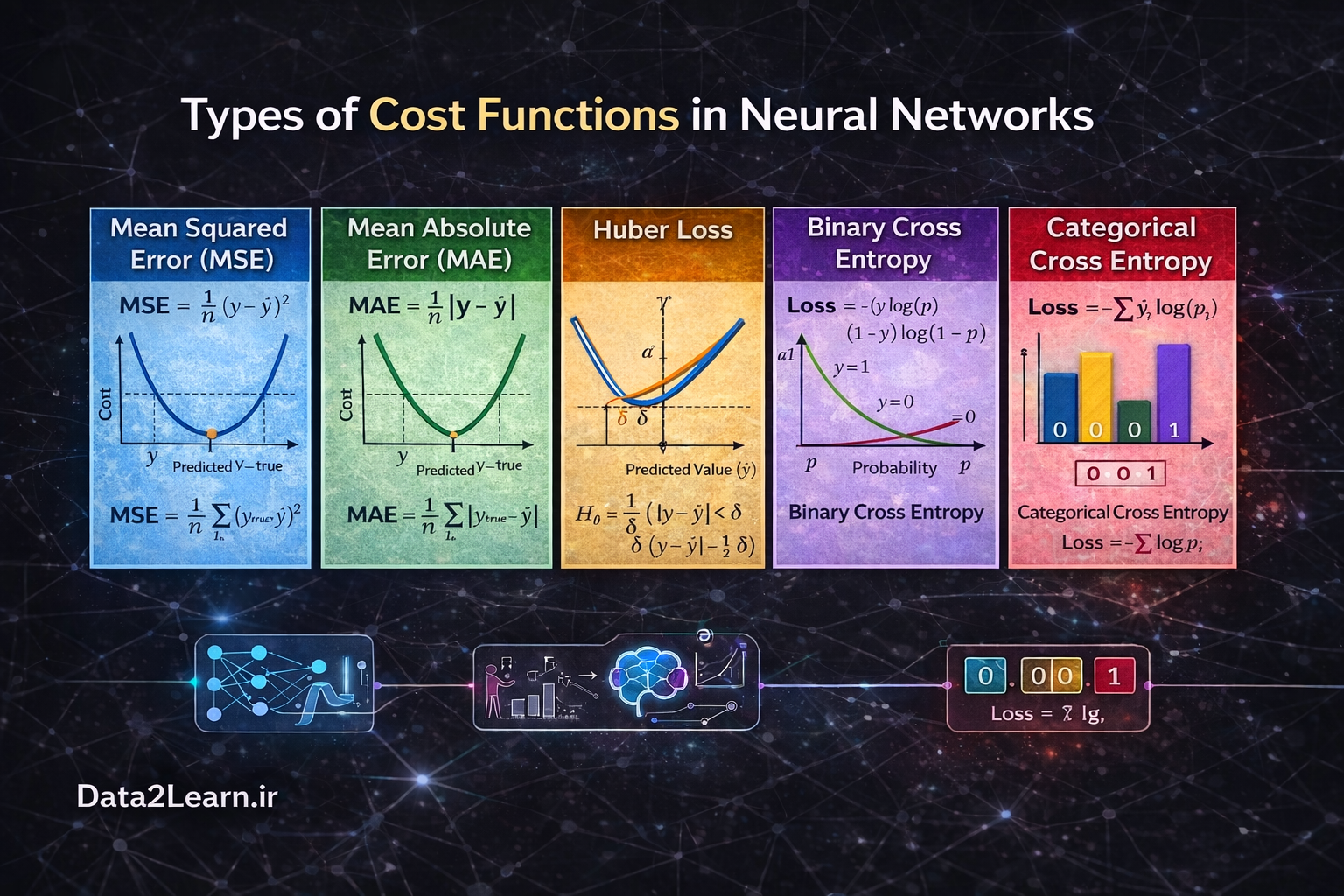
1️⃣ Mean Squared Error (MSE)
تابع MSE یکی از رایجترین توابع هزینه در مسائل رگرسیون است. در مسائل رگرسیون، خروجی مدل یک مقدار عددی پیوسته است؛ مانند پیشبینی قیمت خانه، دما یا میزان فروش. در MSE، اختلاف بین مقدار واقعی و مقدار پیشبینیشده محاسبه شده و سپس به توان دو میرسد. میانگین این مقادیر، مقدار نهایی خطا را تشکیل میدهد.
نکته مهم این است که مربع کردن خطا باعث میشود خطاهای بزرگ بهشدت جریمه شوند. به عنوان مثال، اگر مدل به جای 10 مقدار 20 پیشبینی کند، خطای آن 10 است و مربع آن 100 میشود. اما اگر خطا 2 باشد، مربع آن فقط 4 خواهد بود. بنابراین خطاهای بزرگ تأثیر بسیار بیشتری روی مقدار نهایی خواهند داشت.
مزیت MSE این است که کاملاً مشتقپذیر و برای بهینهسازی بسیار مناسب است. اما عیب بزرگ آن حساسیت زیاد به دادههای پرت (Outliers) است. اگر حتی یک نمونه با خطای بسیار بزرگ در دادهها وجود داشته باشد، ممکن است کل فرآیند آموزش تحت تأثیر قرار گیرد.

2️⃣ Mean Absolute Error (MAE)
تابع MAE نیز در مسائل رگرسیون استفاده میشود، اما بهجای مربع کردن خطا، قدر مطلق اختلاف را محاسبه میکند. در اینجا اگر خطا 5 باشد، همان 5 در نظر گرفته میشود و دیگر به 25 تبدیل نمیشود. همین موضوع باعث میشود MAE نسبت به MSE در برابر دادههای پرت مقاومتر باشد.
به بیان ساده، MAE خطاها را بهصورت خطی جریمه میکند، در حالی که MSE آنها را بهصورت درجه دوم جریمه میکند.
با این حال، MAE یک مشکل دارد: مشتق آن در نقطه صفر ناپیوسته است. این موضوع باعث میشود فرآیند بهینهسازی کمی سختتر از MSE باشد. به همین دلیل در بسیاری از کاربردهای استاندارد، MSE ترجیح داده میشود؛ مگر زمانی که دادهها نویز یا Outlier زیادی داشته باشند.

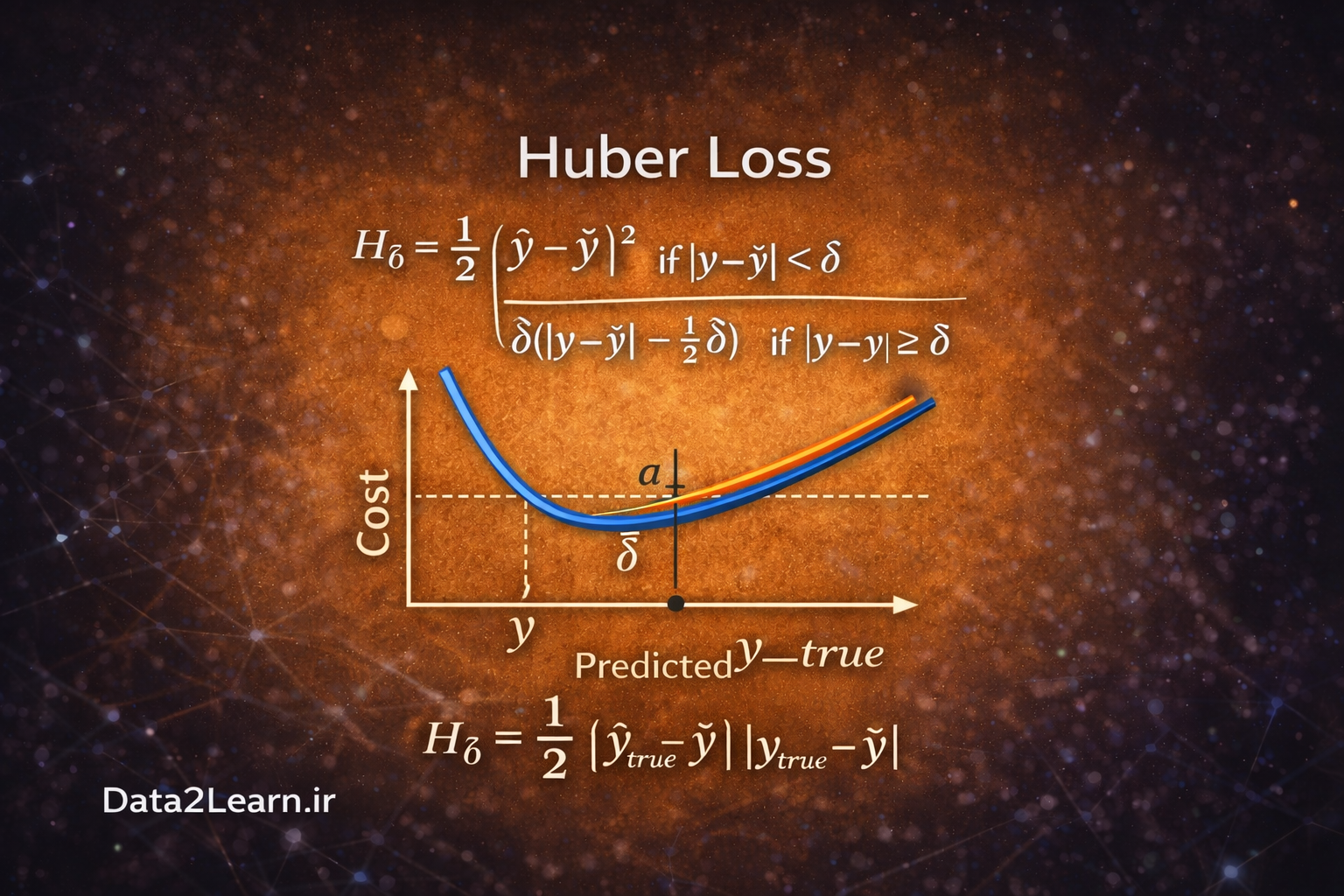
3️⃣ Huber Loss
تابع Huber ترکیبی هوشمندانه از MSE و MAE است. این تابع تلاش میکند بهترین ویژگیهای هر دو را داشته باشد. در Huber Loss اگر خطا کوچک باشد، مانند MSE رفتار میکند (یعنی مربع خطا را محاسبه میکند). اما اگر خطا از یک مقدار آستانه مشخص بزرگتر شود، رفتار آن مانند MAE خواهد بود (خطی میشود).
این ویژگی باعث میشود:
برای خطاهای کوچک، گرادیان نرم و پایدار داشته باشیم.
برای خطاهای بزرگ، حساسیت بیشازحد به Outlier نداشته باشیم.
به همین دلیل Huber Loss در بسیاری از کاربردهای صنعتی و سیستمهای یادگیری عمیق ترجیح داده میشود.
4️⃣ Binary Cross Entropy (Log Loss)
در مسائل طبقهبندی دودویی، خروجی مدل یک احتمال بین 0 و 1 است. برای مثال:
ایمیل اسپم یا غیر اسپم
بیماری دارد یا ندارد
شیء وجود دارد یا ندارد
در اینجا از Binary Cross Entropy استفاده میشود. این تابع بر اساس مفهوم آنتروپی در نظریه اطلاعات تعریف شده است و میزان اختلاف بین احتمال پیشبینیشده و برچسب واقعی را اندازهگیری میکند.
ویژگی بسیار مهم این تابع این است که پیشبینیهای اشتباه با اطمینان بالا را شدیداً جریمه میکند.
مثلاً:
اگر مقدار واقعی 0 باشد اما مدل با اطمینان 0.99 پیشبینی کند که کلاس 1 است، مقدار خطا بسیار بزرگ خواهد بود. این ویژگی باعث میشود مدل بهمرور یاد بگیرد احتمالهای دقیقتری تولید کند، نه فقط برچسب درست.

5️⃣ Categorical Cross Entropy
در مسائل چندکلاسه (مثلاً تشخیص ارقام 0 تا 9)، خروجی مدل یک بردار احتمال است. در اینجا از Categorical Cross Entropy استفاده میشود.
این تابع میزان فاصله بین توزیع احتمال واقعی (که معمولاً به صورت one-hot encoding است) و توزیع احتمال پیشبینیشده توسط مدل را اندازه میگیرد.
معمولاً این تابع همراه با Softmax Activation استفاده میشود. Softmax خروجیها را به یک توزیع احتمال معتبر تبدیل میکند (جمع احتمالها برابر با 1 میشود).
اگر مدل برای کلاس صحیح احتمال بالا بدهد، مقدار خطا کم خواهد بود. اگر احتمال کلاس اشتباه بالا باشد، جریمه شدید اعمال میشود.

6️⃣ Sparse Categorical Cross Entropy
این تابع مشابه Categorical Cross Entropy است، اما تفاوت آن در نحوه نمایش برچسبهاست.
در حالت عادی، اگر 5 کلاس داشته باشیم و کلاس درست عدد 3 باشد، برچسب به صورت: [0, 0, 0, 1, 0] نمایش داده میشود (one-hot).
اما در Sparse نسخه، فقط عدد 3 ذخیره میشود. این باعث مصرف حافظه کمتر و پیادهسازی سادهتر میشود، مخصوصاً زمانی که تعداد کلاسها زیاد باشد.

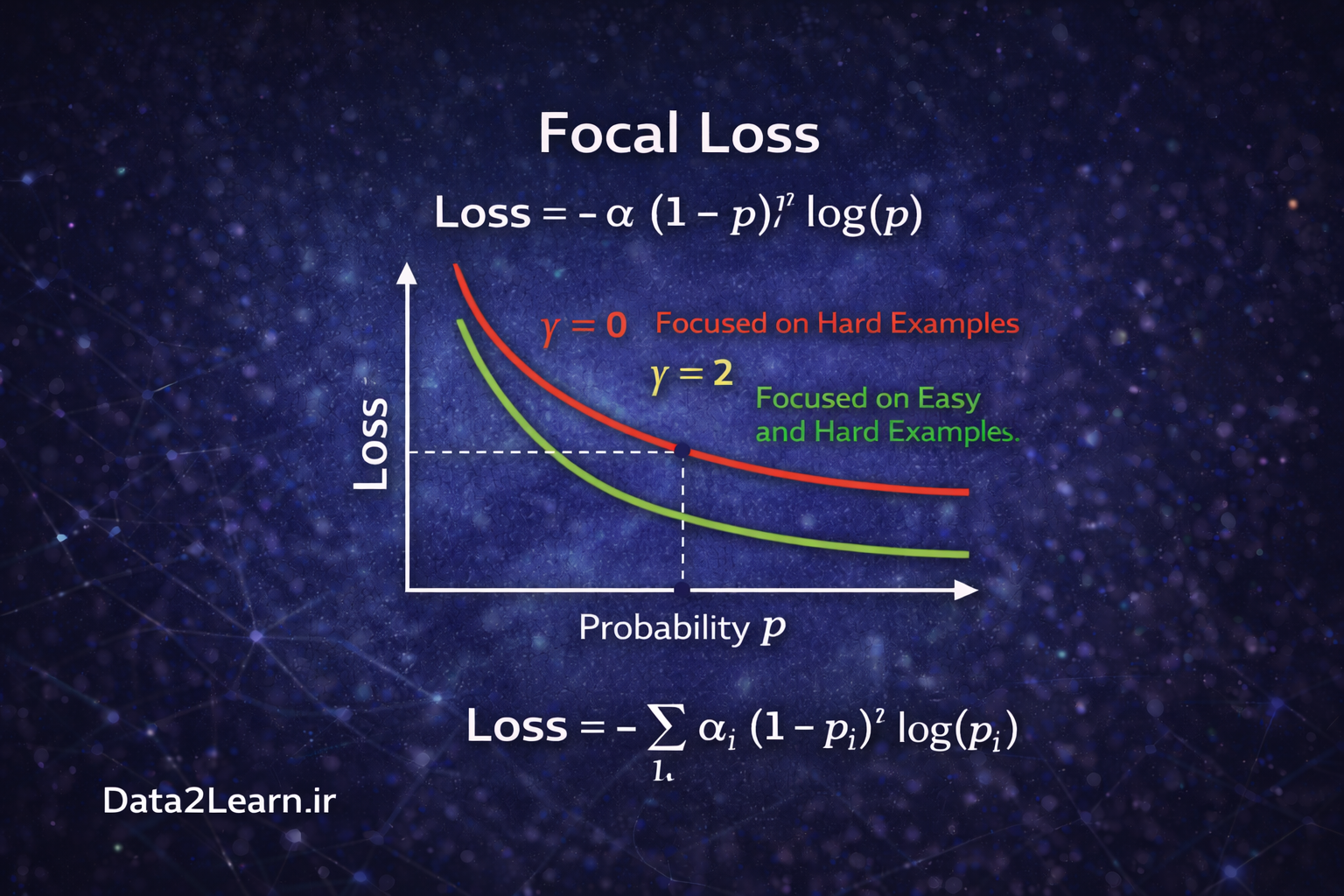
7️⃣ Focal Loss
در بسیاری از مسائل مانند Object Detection، دادهها نامتوازن هستند. مثلاً در یک تصویر ممکن است هزاران پیکسل پسزمینه و فقط چند پیکسل مربوط به شیء وجود داشته باشد. در این شرایط، Cross Entropy معمولی ممکن است بیش از حد روی نمونههای آسان تمرکز کند.
Focal Loss این مشکل را حل میکند. این تابع تمرکز بیشتری روی نمونههای سخت و اشتباه میگذارد و نمونههای آسان را کمتر جریمه میکند. به همین دلیل در مدلهایی مانند RetinaNet و برخی نسخههای YOLO استفاده میشود.
8️⃣ Dice Loss
Dice Loss بیشتر در مسائل Segmentation (بخشبندی تصویر) کاربرد دارد، بهخصوص در تصاویر پزشکی.
در اینجا بهجای مقایسه پیکسل به پیکسل، میزان همپوشانی بین ناحیه پیشبینیشده و ناحیه واقعی اندازهگیری میشود.
اگر همپوشانی زیاد باشد، مقدار Loss کم خواهد بود.
این تابع در شرایطی که کلاسها بسیار نامتوازن باشند (مثلاً تومور کوچک در تصویر بزرگ MRI) عملکرد بسیار خوبی دارد.

دیدگاههای مقاله
۰ دیدگاه تایید شدههنوز دیدگاهی ثبت نشده است
اولین نظر یا سوالت درباره این مقاله را بنویس.