
شبکههای عصبی در سادهترین حالت، فقط «ترکیبکردن» ورودیها هستند؛ یعنی ویژگیها را با وزنها قاطی میکنند و نتیجه را جلو میبرند. مشکل اینجاست که اگر بین این ترکیبها یک مرحلهی غیرخطی نگذاریم، حتی اگر شبکه ۵۰ لایه هم داشته باشد، در نهایت رفتارش خیلی شبیه یک مدل خطی میشود؛ یعنی فقط میتواند الگوهای ساده و مستقیم را خوب یاد بگیرد و روی روابط پیچیدهتر کم میآورد. اینجاست که Activation Function (تابع فعالساز) وارد میشود . تابعی که بعد از هر لایه (یا بخشهایی از شبکه) قرار میگیرد تا خروجی آن لایه را «خم» کند، مرزها را منعطفتر کند، و به شبکه اجازه بدهد روابط پیچیدهی دنیای واقعی را یاد بگیرد.
بهزبان ساده:
بدون فعالساز → شبکه معمولاً قدرت کمی برای مدلکردن پیچیدگیها دارد
با فعالساز → شبکه میتواند الگوهای غیرخطی، تصمیمگیریهای پیچیده و ویژگیهای سطحبالا را بسازد
معیارهای انتخاب یک فعالساز خوب
برای انتخاب یک فعالساز (Activation Function) خوب باید دنبال تابعی باشیم که هم یادگیری را پایدار و سریع نگه دارد و هم در شبکههای عمیق باعث از بین رفتن گرادیان نشود؛ چون اگر گرادیان خیلی کوچک شود (vanishing) یا نورونها از کار بیفتند (مثل dead ReLU)، مدل عملاً کند یا متوقف یاد میگیرد. همچنین باید با نوع معماری (CNN/Transformer/RNN)، محدودیتهای محاسباتی و مهمتر از همه با نوع خروجی مسئله (رگرسیون یا طبقهبندی) هماهنگ باشد تا خروجی معنا و رفتار درست داشته باشد. از این رو فاکتور های مورد نظر ما شامل این موارد خواهد بود :
گرادیان سالم (جلوگیری از vanishing/exploding)
اشباع نشدن در بازههای بزرگ ورودی
جلوگیری از dead neurons (خصوصاً در ReLU)
سرعت و هزینه محاسباتی مناسب
سازگاری با معماری و نرمالسازیها (BatchNorm/LayerNorm)
انتخاب درست برای لایه خروجی (باینری/چندکلاسه/رگرسیون)
پایداری عددی (خصوصاً در آموزشهای طولانی یا FP16)
ReLU (Rectified Linear Unit)
سادهترین و پرکاربردترین فعالساز
برای ورودیهای منفی خروجی صفر میدهد
سریع و بسیار مناسب برای CNN و MLP
مزایا:
سرعت بالا
کاهش مشکل vanishing gradient
پیادهسازی ساده
معایب:
مشکل Dead ReLU (نورونهایی که همیشه صفر میمانند)
📌 انتخاب پیشفرض برای اکثر مدلهای کلاسیک

Leaky ReLU
نسخهی اصلاحشدهی ReLU
در ناحیه منفی شیب کوچک دارد (بهجای صفر کامل)
مزایا:
کاهش مشکل Dead ReLU
هنوز سریع و ساده
معایب:
نیاز به تنظیم ضریب ناحیه منفی
📌 اگر ReLU نورونها را از کار میاندازد، گزینهی بعدی منطقی است

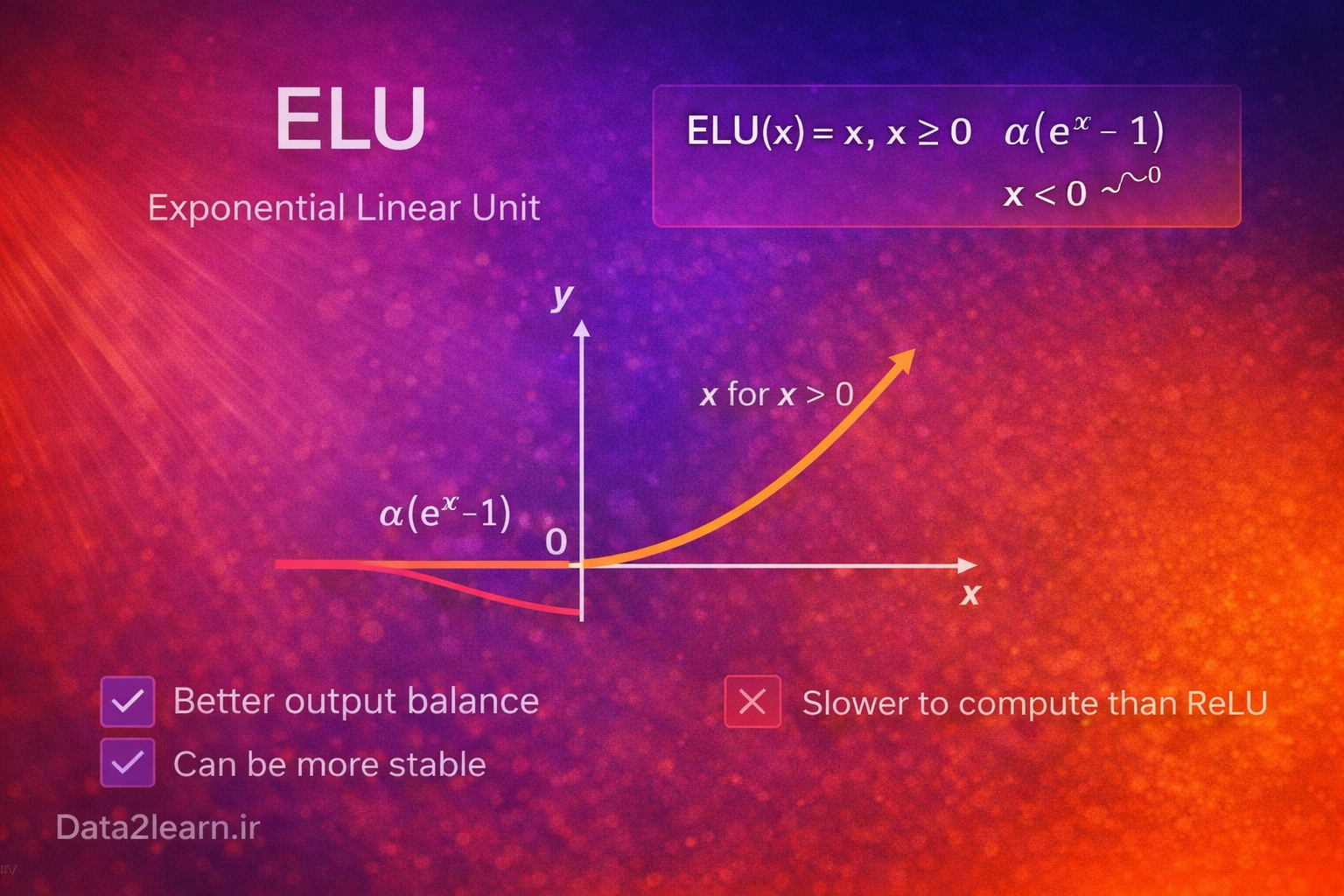
ELU (Exponential Linear Unit)
در ناحیه منفی بهصورت نرم و نمایی کاهش مییابد
میانگین فعالسازیها را به صفر نزدیکتر میکند
مزایا:
یادگیری پایدارتر نسبت به ReLU
خروجیها متعادلتر (نزدیک صفر)
معایب:
محاسبات سنگینتر از ReLU
📌 مناسب زمانی که پایداری مهمتر از سرعت خام است
GELU (Gaussian Error Linear Unit)
رفتار نرمتر و احتمالاتیتر نسبت به ReLU
در مدلهای بزرگ و مدرن بسیار رایج است
مزایا:
گرادیان نرمتر
عملکرد عالی در مدلهای عمیق
معایب:
محاسبات پیچیدهتر
📌 انتخاب رایج در Transformerها و مدلهای بزرگ

SiLU / Swish
ترکیبی نرم از ورودی و sigmoid
رفتار صاف و پیوسته
مزایا:
عملکرد بهتر در برخی شبکههای عمیق
کاهش نوسان گرادیان
معایب:
کمی سنگینتر از ReLU
📌 گزینهی مدرن و جایگزین قوی برای ReLU در بسیاری از معماریها

در نهایت، هیچ Activation Functionای وجود ندارد که در همهی شرایط بهترین باشد؛ انتخاب درست کاملاً به نوع معماری، عمق شبکه و مسئلهی شما بستگی دارد. اگر دنبال یک انتخاب سریع و مطمئن برای اکثر پروژهها هستید، ReLU همچنان استاندارد صنعتی است؛ سریع، ساده و کارآمد. اما اگر با مشکل dead neurons مواجه شدید، Leaky ReLU یا ELU گزینههای منطقیتری هستند.
در مدلهای عمیق و مدرن — بهویژه Transformerها و شبکههای بزرگ — معمولاً GELU و SiLU/Swish عملکرد پایدارتر و گرادیان نرمتری ارائه میدهند و در بسیاری از بنچمارکها نتایج بهتری ثبت کردهاند، هرچند کمی سنگینتر از ReLU هستند.
ReLU: سریعترین و انتخاب پیشفرض
Leaky ReLU: نسخهی امنتر ReLU
ELU: خروجی متعادلتر و پایدارتر
GELU: عالی برای مدلهای عمیق و مدرن
SiLU / Swish: گرادیان نرم و عملکرد قوی در معماریهای جدید
در نهایت، بهترین انتخاب معمولاً با تست تجربی روی دیتاست خودتان مشخص میشود، نه صرفاً تئوری با این حال چند انتخاب مناسب

دیدگاههای مقاله
۰ دیدگاه تایید شدههنوز دیدگاهی ثبت نشده است
اولین نظر یا سوالت درباره این مقاله را بنویس.