
برای آموزش یک مدل YOLO، فقط داشتن مدل کافی نیست. مهمترین بخش کار، داشتن یک دیتاست درست، تمیز و استاندارد است. اگر تصاویر کیفیت خوبی نداشته باشند، لیبلها اشتباه باشند یا ساختار پوشهها درست آماده نشده باشد، حتی بهترین مدل هم خروجی دقیقی نمیدهد.
در این مقاله بهصورت مرحلهبهمرحله یاد میگیریم چطور یک دیتاست مناسب برای آموزش YOLO بسازیم؛ از جمعآوری تصویر و تعیین کلاسها گرفته تا Annotation، ساخت فایلهای لیبل، تقسیم دادهها و آمادهسازی نهایی برای آموزش مدل.
مرحله ۱: جمعآوری تصاویر
اولین قدم برای ساخت دیتاست YOLO، جمعآوری تصاویر مناسب است. تصاویر باید تا حد امکان متنوع باشند تا مدل بتواند شیء موردنظر را در شرایط مختلف یاد بگیرد. اگر فقط از یک زاویه، یک نور یا یک محیط خاص عکس داشته باشید، مدل در همان شرایط خوب عمل میکند اما در تصاویر جدید و متفاوت دچار خطا میشود.
برای مثال اگر میخواهید مدلی برای تشخیص خودرو آموزش دهید، نباید فقط از خودروهای روبهرو و در روز عکس داشته باشید. بهتر است تصاویر شامل خودرو از جلو، عقب، کنار، فاصله نزدیک، فاصله دور، نور روز، شب، باران، خیابان شلوغ و خلوت باشد. این تنوع باعث میشود مدل فقط ظاهر ساده خودرو را حفظ نکند، بلکه مفهوم کلی خودرو را بهتر یاد بگیرد.
منابع جمعآوری تصویر میتواند متفاوت باشد. میتوانید خودتان با دوربین یا موبایل عکس بگیرید، از ویدیوها فریم استخراج کنید، از تصاویر عمومی و مجاز استفاده کنید یا از دیتاستهای آماده کمک بگیرید. نکته مهم این است که تصاویر باید با مسئله واقعی شما نزدیک باشند. اگر قرار است مدل روی دوربین صنعتی، دوربین فروشگاه، دوربین خیابان یا تصویر موبایل کار کند، بهتر است دیتاست هم به همان شرایط نزدیک باشد.
در این مرحله کیفیت تصویر هم اهمیت زیادی دارد. تصاویر خیلی تار، خیلی کوچک، بیش از حد تاریک یا دارای نویز شدید ممکن است باعث یادگیری اشتباه شوند. البته داشتن تعدادی تصویر سخت و واقعی خوب است، اما نباید کل دیتاست از تصاویر بیکیفیت تشکیل شده باشد.
نکات مهم در جمعآوری تصویر:
تصاویر را از زاویههای مختلف جمعآوری کنید.
نورهای متفاوت مثل روز، شب، سایه و نور مصنوعی را در نظر بگیرید.
از پسزمینههای متنوع استفاده کنید.
تصاویر خیلی تکراری را وارد دیتاست نکنید.
اگر شیء در دنیای واقعی گاهی کوچک، دور یا نیمهپوشیده دیده میشود، این حالتها را هم وارد دیتاست کنید.
فقط تصاویر زیبا و واضح انتخاب نکنید؛ دیتاست باید شرایط واقعی را هم پوشش دهد.

مرحله ۲: تعیین کلاسها و ساختار پوشهها
بعد از جمعآوری تصاویر، باید مشخص کنید مدل قرار است چه چیزهایی را تشخیص دهد. هر چیزی که مدل باید تشخیص دهد، یک کلاس محسوب میشود. برای مثال اگر میخواهید مدل شما خودرو، شخص، دوچرخه، سگ و چراغ راهنمایی را تشخیص دهد، اینها کلاسهای دیتاست شما هستند.
تعیین کلاسها باید قبل از برچسبگذاری انجام شود. اگر وسط کار تصمیم بگیرید کلاس جدید اضافه کنید یا نام کلاسها را تغییر دهید، ممکن است مجبور شوید بخشی از لیبلها را دوباره اصلاح کنید. بهتر است از همان ابتدا یک لیست دقیق از کلاسها بسازید و نام آنها را ثابت نگه دارید.
برای YOLO، هر کلاس معمولاً یک شماره دارد. مثلاً:
0: car
1: person
2: bicycle
3: dog
4: traffic_light
این شمارهها در فایل لیبل استفاده میشوند. یعنی اگر در یک تصویر یک خودرو وجود داشته باشد، در فایل لیبل بهجای نوشتن کلمه car، شماره کلاس یعنی 0 ذخیره میشود.
بعد از تعیین کلاسها، باید ساختار پوشههای دیتاست را آماده کنید. ساختار رایج برای YOLO به این شکل است:
dataset/
├── images/
│ ├── train/
│ ├── val/
│ └── test/
│
├── labels/
│ ├── train/
│ ├── val/
│ └── test/
│
└── data.yamlدر پوشه images تصاویر قرار میگیرند و در پوشه labels فایلهای متنی مربوط به لیبلها ذخیره میشوند. نکته مهم این است که برای هر تصویر، یک فایل لیبل با همان نام وجود داشته باشد.
مثلاً اگر تصویر شما این باشد:
images/train/car_001.jpgفایل لیبل آن باید این باشد:
labels/train/car_001.txtاگر نام تصویر و فایل لیبل با هم هماهنگ نباشد، YOLO نمیتواند لیبل مربوط به تصویر را درست پیدا کند.
نکات مهم در این مرحله:
قبل از شروع Annotation، کلاسها را نهایی کنید.
نام کلاسها را ساده، انگلیسی و بدون فاصله بنویسید.
برای هر تصویر، یک فایل txt همنام در پوشه labels داشته باشید.
ساختار train و val را از ابتدا مشخص کنید.
پوشه images و labels باید ساختار مشابه داشته باشند.
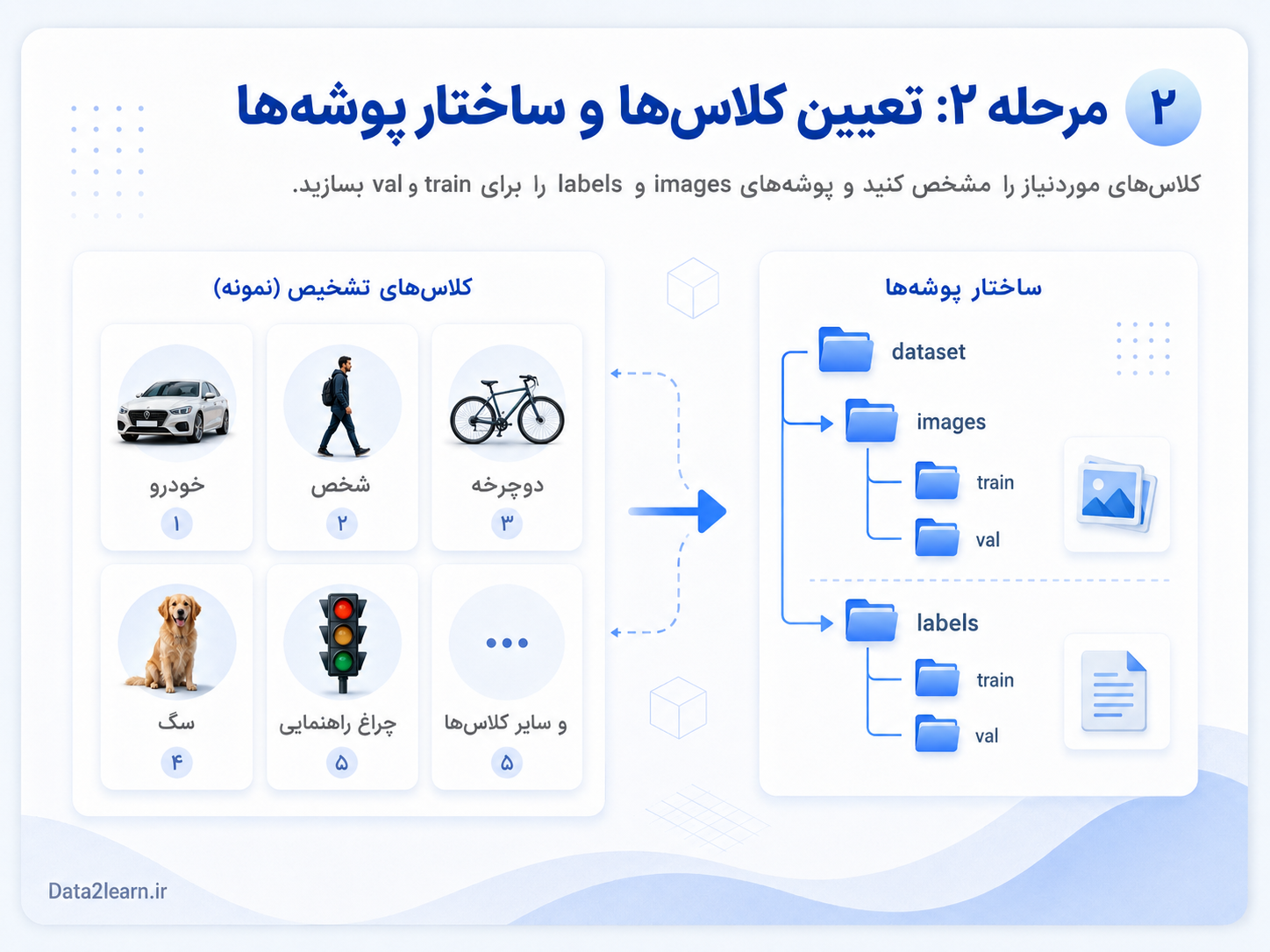
مرحله ۳: Annotation یا برچسبگذاری تصاویر
Annotation یعنی مشخص کنیم در هر تصویر چه شیءهایی وجود دارد و جای دقیق آنها کجاست. در مسئله Object Detection، این کار معمولاً با کشیدن Bounding Box انجام میشود. Bounding Box همان کادر مستطیلی است که دور شیء کشیده میشود.
برای مثال اگر در تصویر یک خودرو، یک شخص و یک دوچرخه وجود داشته باشد، باید دور هر کدام یک کادر جداگانه بکشید و کلاس درست آن را مشخص کنید. خودرو باید با کلاس car، شخص با کلاس person و دوچرخه با کلاس bicycle ذخیره شود.
دقت در Annotation بسیار مهم است. اگر کادرها خیلی بزرگتر از شیء کشیده شوند، مدل یاد میگیرد که بخشی از پسزمینه هم جزو شیء است. اگر کادرها خیلی کوچک باشند و بخشی از شیء بیرون بماند، مدل یادگیری ناقص خواهد داشت. بنابراین Bounding Box باید تا حد ممکن دقیق دور خود شیء قرار بگیرد.
اشتباه رایج در این مرحله این است که بعضی اشیا در تصویر لیبل نمیشوند. برای مثال اگر در تصویر چند خودرو وجود دارد اما فقط یکی از آنها را برچسب بزنید، مدل ممکن است بقیه خودروها را بهعنوان پسزمینه در نظر بگیرد و در آینده در تشخیص آنها ضعیف شود.
برای Annotation میتوانید از ابزارهای مختلف استفاده کنید. ابزارهایی مثل LabelImg، Roboflow، CVAT و Label Studio برای برچسبگذاری تصاویر استفاده میشوند. مهم این است که خروجی ابزار با فرمت YOLO قابل ذخیره باشد.
نکات مهم برای Annotation درست:
دور هر شیء یک Bounding Box دقیق بکشید.
کلاس هر شیء را درست انتخاب کنید.
اشیای کوچک ولی قابل مشاهده را فراموش نکنید.
اگر شیء نصفه دیده میشود ولی قابل تشخیص است، معمولاً باید لیبل شود.
کادر را خیلی بزرگ یا خیلی کوچک نکشید.
تصاویر را چند بار بررسی کنید تا لیبل اشتباه باقی نماند.
مثال:
اگر در تصویر یک سگ وجود دارد، نباید فقط صورت سگ را لیبل کنید. باید کل بدن قابل مشاهده سگ داخل کادر قرار بگیرد. اگر بخشی از بدن پشت مانع است، فقط بخش قابل مشاهده را در نظر بگیرید.
مرحله ۴: فرمت لیبل YOLO
بعد از Annotation، اطلاعات هر شیء در یک فایل متنی با پسوند .txt ذخیره میشود. فرمت لیبل در YOLO ساده است، اما باید دقیق رعایت شود.
هر خط در فایل txt مربوط به یک شیء در تصویر است. ساختار هر خط به این شکل است:
class x_center y_center width heightبرای مثال:
0 0.512 0.463 0.245 0.318این خط یعنی یک شیء از کلاس شماره 0 در تصویر وجود دارد. مقدارهای بعدی موقعیت و اندازه Bounding Box را مشخص میکنند.
معنی هر بخش:
classشماره کلاس است. مثلاً اگر کلاس car شماره 0 باشد، مقدار class برای خودرو برابر 0 میشود.
x_centerمختصات افقی مرکز کادر است. این مقدار بین 0 و 1 نرمالسازی شده است.
y_centerمختصات عمودی مرکز کادر است. این مقدار هم بین 0 و 1 قرار دارد.
widthعرض کادر نسبت به عرض کل تصویر است.
heightارتفاع کادر نسبت به ارتفاع کل تصویر است.
نکته مهم این است که YOLO از مختصات واقعی پیکسلی مثل x1, y1, x2, y2 استفاده نمیکند. مقادیر باید نرمالسازی شده باشند. یعنی بهجای اینکه بگوییم عرض کادر 250 پیکسل است، میگوییم عرض کادر چند درصد از عرض کل تصویر را تشکیل میدهد.
اگر یک تصویر چند شیء داشته باشد، فایل لیبل آن چند خط خواهد داشت. برای مثال:
0 0.512 0.463 0.245 0.318
1 0.231 0.674 0.152 0.289
2 0.768 0.345 0.198 0.256در این مثال تصویر شامل سه شیء است. هر خط یک شیء جداگانه را نشان میدهد.
اگر در یک تصویر هیچ شیء موردنظری وجود نداشته باشد، بسته به روش آموزش و ابزار مورد استفاده، ممکن است فایل لیبل خالی ساخته شود یا اصلاً فایل لیبل وجود نداشته باشد. اما در بسیاری از پروژهها بهتر است ساختار فایلها منظم باشد تا خطای مسیر یا نامگذاری ایجاد نشود.
اشتباهات رایج در فرمت لیبل YOLO:
استفاده از مختصات پیکسلی بهجای مقدار نرمالشده
جابهجا نوشتن width و height
اشتباه بودن شماره کلاس
وجود فاصله یا کاراکتر اضافه در فایل txt
تفاوت نام فایل تصویر و فایل لیبل
ذخیره فایل لیبل در پوشه اشتباه

مرحله ۵: تقسیم دادهها به Train، Validation و Test
بعد از اینکه تصاویر و لیبلها آماده شدند، باید دیتاست را به چند بخش تقسیم کنید. این کار برای این است که مدل فقط روی بخشی از دادهها آموزش ببیند و روی دادههای جداگانه ارزیابی شود.
معمولاً دیتاست به سه بخش تقسیم میشود:
Trainبخشی از دادهها که مدل با آن آموزش میبیند.
Validation یا Valبخشی از دادهها که هنگام آموزش برای بررسی عملکرد مدل استفاده میشود.
Testبخشی از دادهها که بعد از پایان آموزش برای ارزیابی نهایی مدل استفاده میشود.
یک تقسیم رایج میتواند به این شکل باشد:
70% train
20% val
10% testالبته این نسبت همیشه ثابت نیست. اگر دیتاست کوچک باشد، ممکن است بخواهید داده بیشتری برای train نگه دارید. اگر دیتاست بزرگ باشد، میتوانید بخش val و test را هم قویتر در نظر بگیرید.
نکته مهم این است که دادههای train، val و test نباید خیلی شبیه و تکراری باشند. برای مثال اگر از یک ویدیو 100 فریم پشتسرهم استخراج کردهاید، نباید فریمهای خیلی مشابه را بین train و test پخش کنید. چون در این حالت مدل روی تصویری شبیه به داده تست آموزش دیده و نتیجه ارزیابی واقعی نخواهد بود.
بهتر است تصاویر هر بخش از نظر تنوع، کلاسها و شرایط مختلف متعادل باشند. مثلاً اگر در دیتاست شما کلاس dog وجود دارد، نباید تمام تصاویر dog فقط در train باشند و در val هیچ نمونهای از dog وجود نداشته باشد.
نکات مهم در تقسیم دادهها:
دادههای train، val و test را از هم جدا نگه دارید.
تصاویر خیلی مشابه را بین بخشهای مختلف پخش نکنید.
در هر بخش، نمونههایی از کلاسهای مهم داشته باشید.
اگر دیتاست کوچک است، بخش test را خیلی بزرگ نگیرید.
برای ارزیابی واقعی، test باید شامل تصاویر جدید و متفاوت باشد.
مثال ساختار بعد از تقسیم:
dataset/
├── images/
│ ├── train/
│ │ ├── image_001.jpg
│ │ └── image_002.jpg
│ ├── val/
│ │ └── image_101.jpg
│ └── test/
│ └── image_201.jpg
│
├── labels/
│ ├── train/
│ │ ├── image_001.txt
│ │ └── image_002.txt
│ ├── val/
│ │ └── image_101.txt
│ └── test/
│ └── image_201.txt
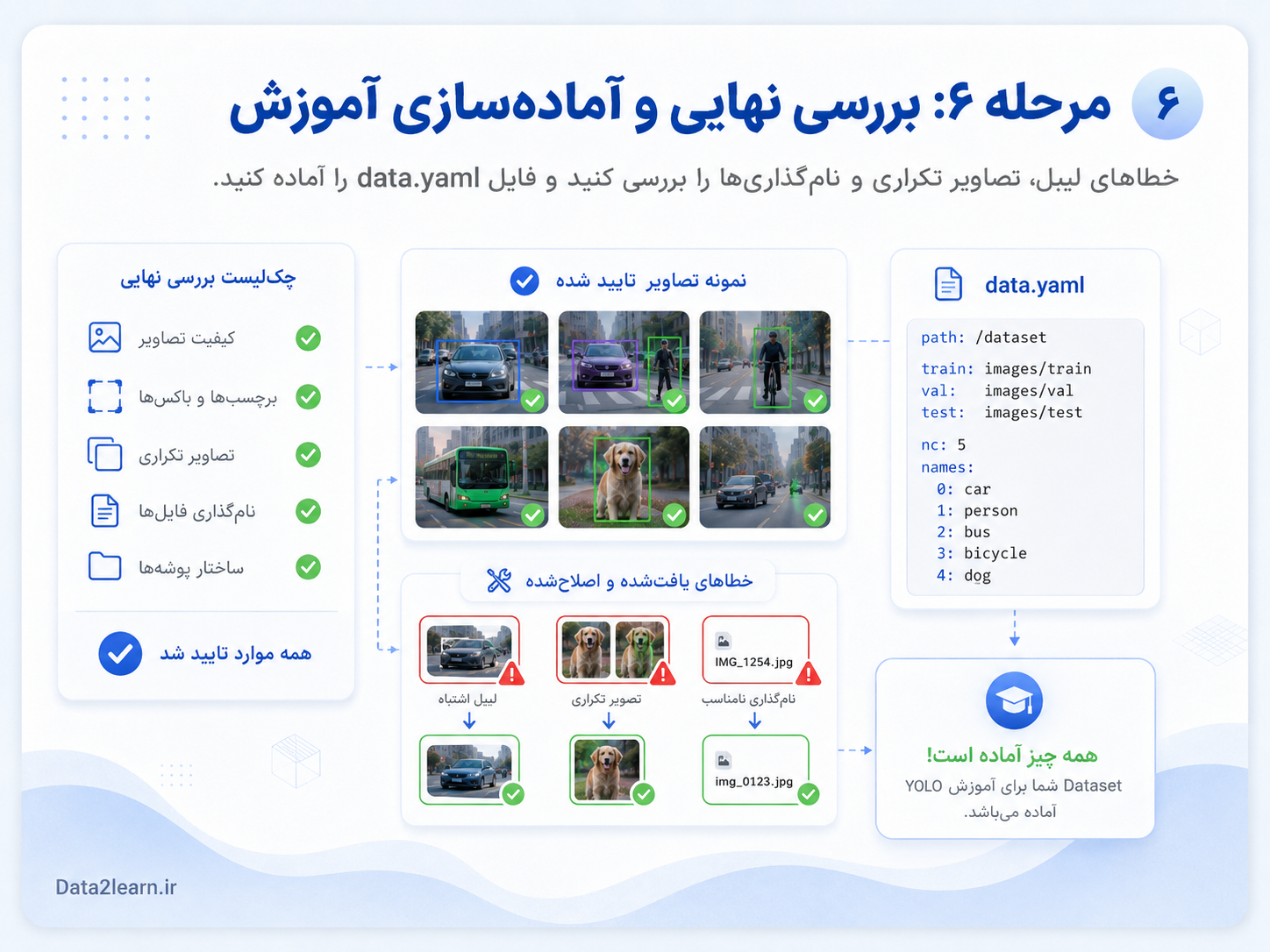
مرحله ۶: بررسی نهایی و آمادهسازی برای آموزش
قبل از شروع آموزش YOLO، باید دیتاست را یک بار کامل بررسی کنید. بسیاری از خطاهای مدل از خود دیتاست شروع میشوند، نه از مدل. اگر لیبلها اشتباه باشند، مسیر پوشهها غلط باشد یا بعضی تصاویر بدون لیبل باشند، آموزش مدل با مشکل روبهرو میشود.
در این مرحله باید چند مورد را بررسی کنید. اول اینکه همه تصاویر کیفیت قابل قبول داشته باشند. دوم اینکه برای هر تصویر، فایل لیبل درست وجود داشته باشد. سوم اینکه Bounding Boxها دقیق باشند و کلاسها اشتباه انتخاب نشده باشند. چهارم اینکه نام فایلها و مسیر پوشهها با هم هماهنگ باشند.
بعد از بررسی تصاویر و لیبلها، باید فایل data.yaml را آماده کنید. این فایل به YOLO میگوید مسیر دیتاست کجاست، تصاویر train و val در کدام پوشه هستند و کلاسهای دیتاست چه نامهایی دارند.
نمونه ساده فایل data.yaml:
path: /dataset
train: images/train
val: images/val
test: images/test
nc: 5
names:
0: car
1: person
2: bicycle
3: dog
4: traffic_lightدر این فایل، path مسیر اصلی دیتاست است. بخش train مسیر تصاویر آموزشی را مشخص میکند. بخش val مسیر تصاویر اعتبارسنجی است. اگر بخش test داشته باشید، مسیر آن هم در test نوشته میشود.
مقدار nc تعداد کلاسهاست. اگر شما 5 کلاس دارید، مقدار آن باید 5 باشد. بخش names هم نام کلاسها را با همان شمارههایی که در فایلهای لیبل استفاده شدهاند مشخص میکند.
اگر شماره کلاسها در فایل لیبل با ترتیب کلاسها در data.yaml هماهنگ نباشد، مدل اشتباه آموزش میبیند. برای مثال اگر در فایل txt عدد 0 برای خودرو استفاده شده اما در data.yaml عدد 0 برای شخص تعریف شده باشد، مدل خودرو را با نام شخص یاد میگیرد.
چکلیست نهایی قبل از آموزش:
آیا همه تصاویر در مسیر درست قرار دارند؟
آیا برای هر تصویر فایل txt همنام وجود دارد؟
آیا کلاسها درست شمارهگذاری شدهاند؟
آیا فایل data.yaml با دیتاست هماهنگ است؟
آیا تصاویر تکراری زیاد حذف شدهاند؟
آیا لیبلهای اشتباه اصلاح شدهاند؟
آیا train و val بهدرستی جدا شدهاند؟
آیا نام فایلها ساده و بدون مشکل هستند؟
بعد از این بررسیها، دیتاست شما برای آموزش YOLO آماده است.
اشتباهات رایج در ساخت دیتاست YOLO
ساخت دیتاست شاید در ظاهر ساده به نظر برسد، اما اشتباهات کوچک در همین مرحله میتواند باعث شود مدل خروجی ضعیفی داشته باشد. یکی از رایجترین اشتباهات، کم بودن تنوع تصاویر است. اگر مدل فقط یک نوع تصویر ببیند، در شرایط واقعی خوب عمل نمیکند.
اشتباه دیگر، لیبلگذاری ناهماهنگ است. مثلاً در بعضی تصاویر فقط بخش اصلی شیء لیبل میشود و در بعضی دیگر کل شیء. این ناهماهنگی باعث میشود مدل دقیق یاد نگیرد مرز شیء کجاست.
گاهی هم شماره کلاسها اشتباه وارد میشود. این خطا بسیار خطرناک است، چون ممکن است مدل از نظر عددی آموزش ببیند اما نام کلاسها را اشتباه یاد بگیرد. برای جلوگیری از این مشکل باید فایلهای لیبل و data.yaml چند بار بررسی شوند.
تصاویر تکراری هم مشکلساز هستند. اگر تعداد زیادی تصویر مشابه وارد دیتاست کنید، مدل بهجای یادگیری عمومی، روی همان شرایط خاص بیش از حد وابسته میشود.
جمعبندی
برای ساخت یک مدل YOLO دقیق، باید از دیتاست شروع کنید. مدل خوب بدون دیتاست خوب نتیجه مناسبی نمیدهد. یک دیتاست استاندارد باید تصاویر متنوع، لیبلهای دقیق، ساختار پوشه منظم، فرمت لیبل صحیح و فایل data.yaml درست داشته باشد.
مراحل اصلی ساخت دیتاست YOLO شامل جمعآوری تصاویر، تعیین کلاسها، ساختاردهی پوشهها، Annotation، ذخیره لیبلها با فرمت YOLO، تقسیم دادهها و بررسی نهایی است. اگر این مراحل با دقت انجام شوند، مدل در زمان آموزش بهتر یاد میگیرد و در تستهای واقعی عملکرد دقیقتری خواهد داشت.
دیدگاههای مقاله
۰ دیدگاه تایید شدههنوز دیدگاهی ثبت نشده است
اولین نظر یا سوالت درباره این مقاله را بنویس.