
در این مقاله، مرحله به مرحله یاد میگیریم چطور مدل YOLO را با یک دیتاست اختصاصی یا یک دیتاست واقعی کوچک مثل COCO8 آموزش دهیم؛ از نصب محیط و ساخت فایل data.yaml گرفته تا اجرای Train، بررسی معیارها، تست مدل و ذخیره خروجی نهایی.
YOLO Train یعنی چه؟
Train کردن YOLO یعنی مدل را با تصاویر و لیبلهای دیتاست آموزش دهیم تا بتواند اشیای مشخصشده را در تصاویر جدید پیدا کند. برای مثال اگر دیتاست شامل کلاسهای car، person، bus و motorcycle باشد، مدل بعد از آموزش باید بتواند این اشیا را در تصویر جدید تشخیص دهد.
در روند آموزش، مدل چندین بار تصاویر را میبیند، خطای خود را محاسبه میکند و وزنهای داخلی خود را تغییر میدهد تا خروجی دقیقتری تولید کند.
دیتاست نمونه در این آموزش
در این آموزش میتوانیم از یک دیتاست واقعی کوچک به نام COCO8 استفاده کنیم. این دیتاست نسخه بسیار کوچکشدهای از COCO است و برای تست سریع، دیباگ و اطمینان از درست بودن روند آموزش مناسب است.
COCO8 شامل تعداد کمی تصویر برای train و val است و به همین دلیل برای شروع، تست کدها و بررسی pipeline گزینه خوبی محسوب میشود.
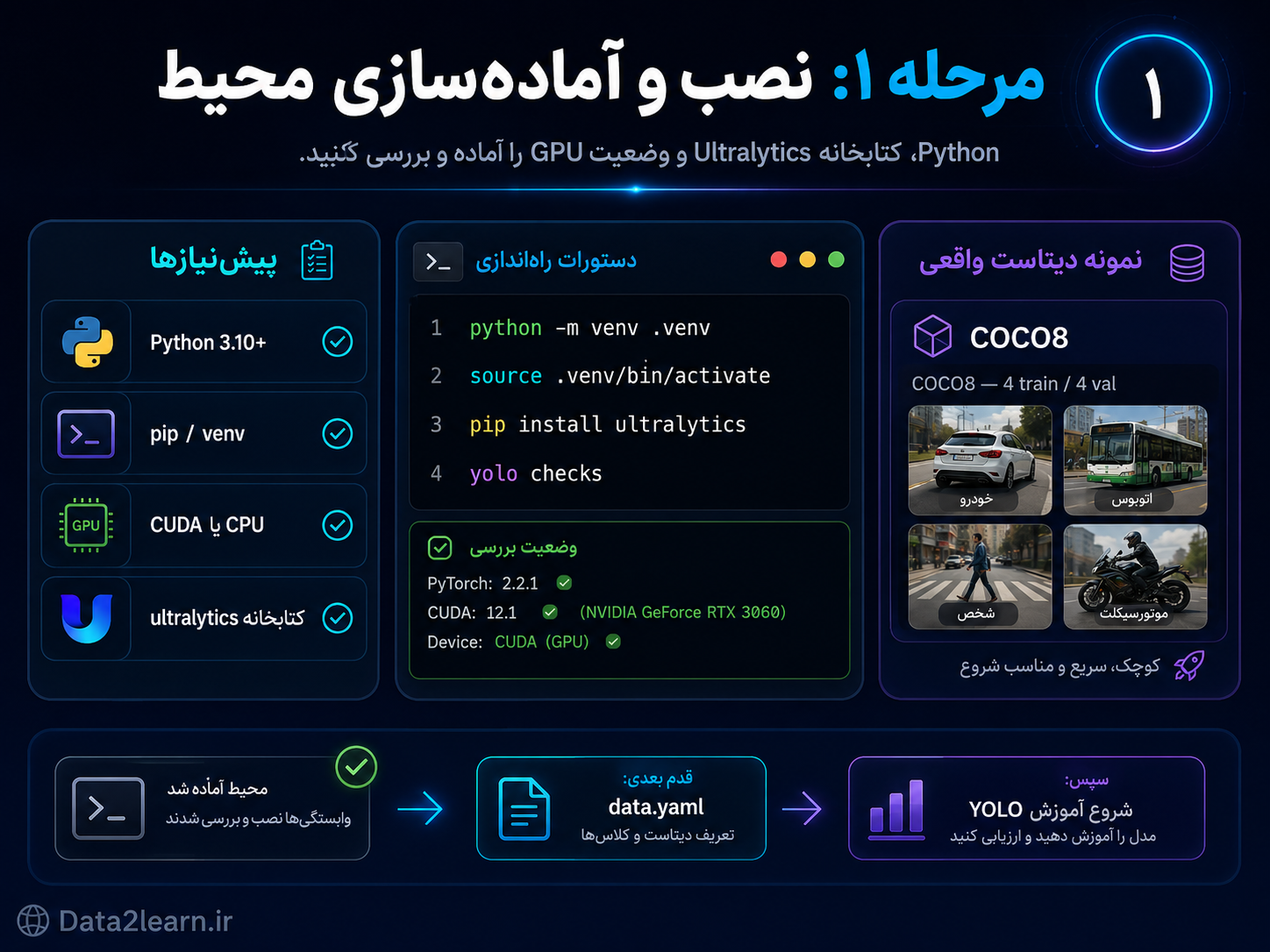
مرحله ۱: نصب و آمادهسازی محیط
اولین قدم برای Train کردن YOLO، آمادهسازی محیط است. برای این کار به Python، ابزار pip، محیط مجازی و کتابخانه ultralytics نیاز داریم.
بهتر است پروژه را داخل یک محیط مجازی اجرا کنید تا پکیجهای آن با بقیه پروژههای سیستم تداخل نداشته باشند.
دستورات نصب
python -m venv .venv
source .venv/bin/activate
pip install ultralytics
yolo checksدر ویندوز، فعالسازی محیط مجازی معمولاً به این شکل است:
.venv\Scripts\activateدستور زیر هم وضعیت نصب و سختافزار را بررسی میکند:
yolo checksاین دستور نشان میدهد که کتابخانهها درست نصب شدهاند یا نه، PyTorch در دسترس است یا نه، و آیا سیستم از GPU استفاده میکند یا روی CPU اجرا میشود.
در این مرحله چه چیزهایی بررسی میشود؟
نصب بودن Python
فعال بودن محیط مجازی
نصب بودن کتابخانه
ultralyticsوضعیت PyTorch
وضعیت CUDA یا CPU
آماده بودن سیستم برای Train
اگر GPU داشته باشید، آموزش سریعتر انجام میشود. اگر GPU در دسترس نباشد، مدل روی CPU هم قابل آموزش است، اما زمان بیشتری نیاز دارد.
مرحله ۲: ساخت و بررسی فایل data.yaml
برای اینکه YOLO بتواند دیتاست را بخواند، باید یک فایل به نام data.yaml داشته باشیم. این فایل مسیر تصاویر، مسیر validation و نام کلاسها را مشخص میکند.
بدون این فایل، YOLO نمیداند تصاویر آموزشی کجا هستند و هر شماره کلاس مربوط به چه چیزی است.
ساختار رایج دیتاست YOLO
dataset/
├── images/
│ ├── train/
│ └── val/
│
├── labels/
│ ├── train/
│ └── val/
│
└── data.yamlدر این ساختار، تصاویر داخل پوشه images و فایلهای لیبل داخل پوشه labels قرار میگیرند.
برای هر تصویر، باید یک فایل لیبل همنام در پوشه labels وجود داشته باشد.
مثلاً:
images/train/image_001.jpg
labels/train/image_001.txtاگر نام تصویر و لیبل هماهنگ نباشد، YOLO نمیتواند لیبل تصویر را درست پیدا کند.
نمونه فایل data.yaml
path: /home/user/my_dataset
train: images/train
val: images/val
names:
0: person
1: bicycle
2: car
3: motorcycleتوضیح بخشهای فایل
path
مسیر اصلی دیتاست را مشخص میکند.
path: /home/user/my_datasettrain
مسیر تصاویر آموزشی را نسبت به path مشخص میکند.
train: images/trainval
مسیر تصاویر اعتبارسنجی را مشخص میکند.
val: images/valnames
نام کلاسها را مشخص میکند.
names:
0: person
1: bicycle
2: car
3: motorcycleشماره کلاسها در این بخش باید دقیقاً با شماره کلاسهایی که داخل فایلهای txt لیبل استفاده شدهاند هماهنگ باشد.
نمونه واقعی با COCO8
برای تست سریع میتوانید از coco8.yaml استفاده کنید. در این حالت YOLO خودش دیتاست کوچک COCO8 را دریافت و آماده میکند.
نمونه سادهشده ساختار آن:
path: coco8
train: images/train
val: images/val
names:
0: person
1: bicycle
2: car
3: motorcycle
4: airplane
5: busبرای شروع آموزش و تست pipeline، استفاده از COCO8 انتخاب خوبی است، چون کوچک است و سریع اجرا میشود.
چکلیست بررسی data.yaml
مسیر
pathدرست باشد.پوشه
images/trainوجود داشته باشد.پوشه
images/valوجود داشته باشد.پوشه
labels/trainوجود داشته باشد.پوشه
labels/valوجود داشته باشد.شماره کلاسها با لیبلها هماهنگ باشد.
نام فایل تصویر و لیبل یکسان باشد.

مرحله ۳: اجرای Train
بعد از آماده شدن محیط و فایل data.yaml، میتوانیم آموزش مدل را شروع کنیم. برای Train کردن YOLO دو روش رایج وجود دارد:
اجرای آموزش با Python
اجرای آموزش با CLI
هر دو روش درست هستند. اگر میخواهید داخل پروژه پایتونی خودتان کنترل بیشتری داشته باشید، روش Python بهتر است. اگر فقط میخواهید سریع مدل را آموزش دهید، CLI سادهتر است.
آموزش با Python
from ultralytics import YOLO
model = YOLO("yolo11n.pt")
results = model.train(
data="coco8.yaml",
epochs=50,
imgsz=640,
batch=16
)توضیح کد
در خط اول، کلاس YOLO را از کتابخانه ultralytics وارد میکنیم.
from ultralytics import YOLOبعد یک مدل پایه بارگذاری میکنیم:
model = YOLO("yolo11n.pt")این مدل از قبل آموزش دیده و ما آن را روی دیتاست خودمان fine-tune میکنیم.
سپس آموزش را شروع میکنیم:
results = model.train(
data="coco8.yaml",
epochs=50,
imgsz=640,
batch=16
)آموزش با CLI
yolo detect train data=coco8.yaml model=yolo11n.pt epochs=50 imgsz=640 batch=16این دستور همان کاری را انجام میدهد که کد Python انجام داد، اما مستقیماً از ترمینال اجرا میشود.
پارامترهای مهم Train
data
مسیر فایل data.yaml را مشخص میکند.
data=coco8.yamlاگر دیتاست اختصاصی دارید، مسیر فایل خودتان را قرار دهید:
data=/home/user/my_dataset/data.yamlmodel
مدل پایه را مشخص میکند.
model=yolo11n.ptمدلهای سبکتر مثل نسخه n برای شروع سریع و تست مناسبتر هستند.
epochs
تعداد دفعاتی است که مدل کل دیتاست را میبیند.
epochs=50اگر مقدار خیلی کم باشد، مدل خوب یاد نمیگیرد. اگر خیلی زیاد باشد، ممکن است overfit شود.
imgsz
اندازه تصویر ورودی به مدل است.
imgsz=640عدد 640 یکی از اندازههای رایج برای YOLO است.
batch
تعداد تصویرهایی است که در هر مرحله وارد مدل میشوند.
batch=16اگر GPU حافظه کمی دارد، مقدار batch را کمتر کنید.
device
برای انتخاب GPU یا CPU استفاده میشود.
device=0یا برای CPU:
device=cpuنمونه کاملتر کد Train
from ultralytics import YOLO
model = YOLO("yolo11n.pt")
results = model.train(
data="coco8.yaml",
epochs=50,
imgsz=640,
batch=16,
device=0,
workers=4,
patience=20,
project="runs/custom_yolo",
name="exp1"
)توضیح چند پارامتر اضافه
workers
تعداد پردازشهایی که برای خواندن دادهها استفاده میشود.
workers=4patience
اگر مدل بعد از چند epoch بهتر نشود، آموزش زودتر متوقف میشود.
patience=20project
مسیر ذخیره خروجیها را مشخص میکند.
project="runs/custom_yolo"name
نام اجرای آموزش را مشخص میکند.
name="exp1"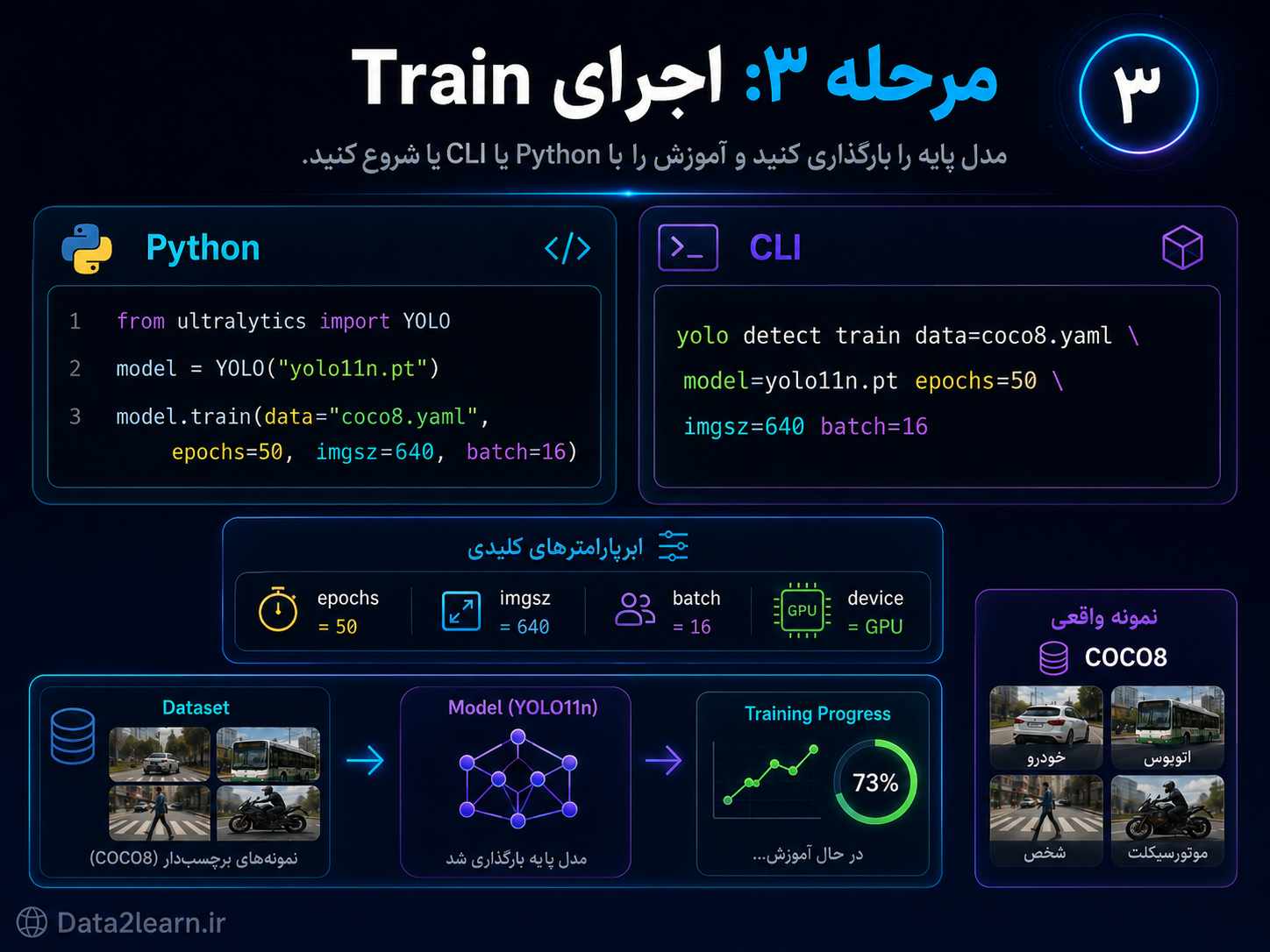
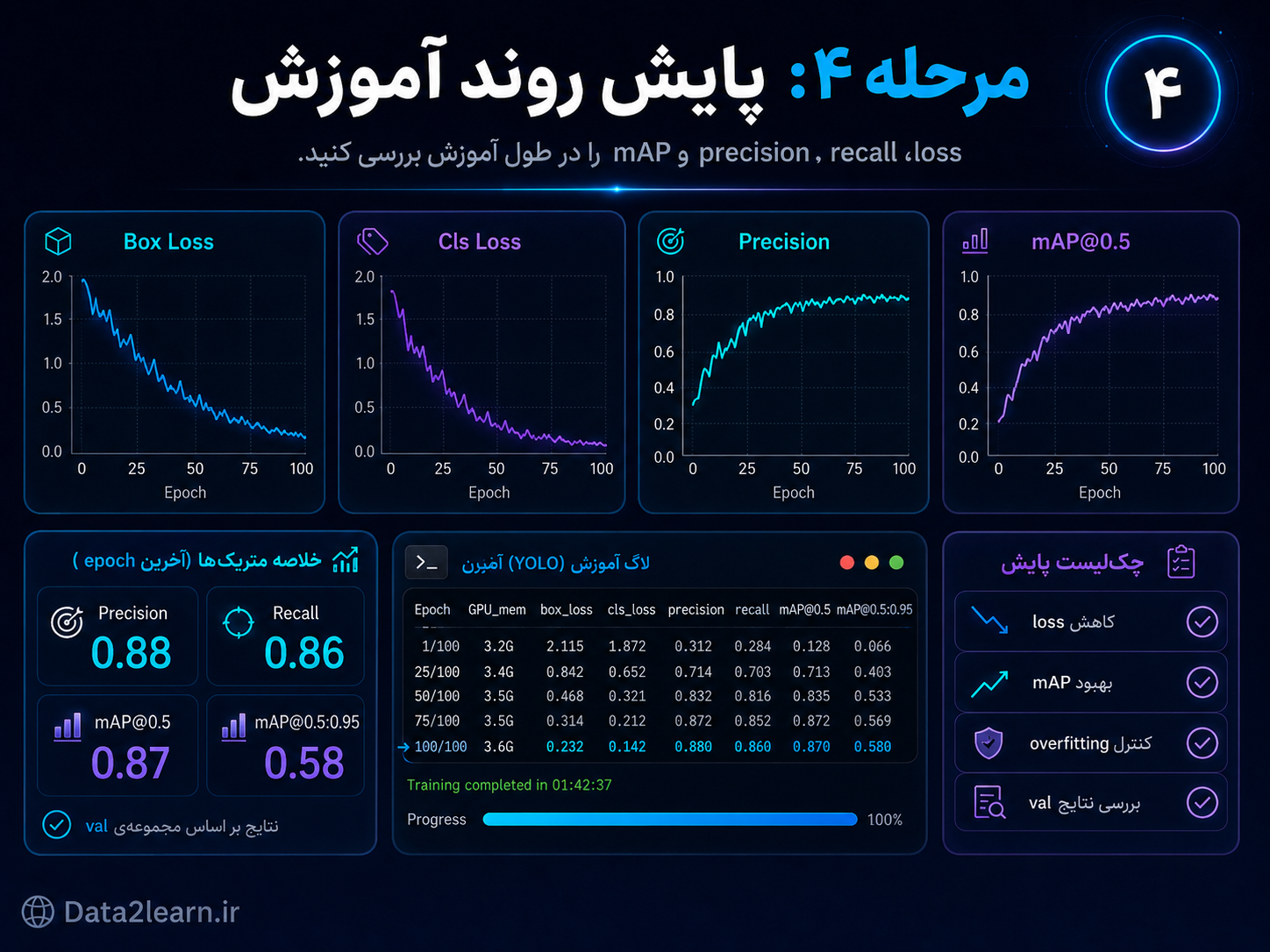
مرحله ۴: پایش روند آموزش
بعد از شروع آموزش، باید روند یادگیری مدل را بررسی کنید. فقط اینکه Train بدون خطا اجرا شود کافی نیست. باید ببینید loss کم میشود یا نه، precision و recall بهتر میشوند یا نه، و mAP رشد میکند یا نه.
YOLO در طول آموزش، فایلها و نمودارهای مختلفی تولید میکند که برای تحلیل روند مدل بسیار مهم هستند.
معیارهای مهم در آموزش YOLO
box_loss
این معیار نشان میدهد مدل در پیدا کردن محل دقیق Bounding Box چقدر خطا دارد.
اگر box_loss کم شود، یعنی مدل بهتر یاد گرفته محل اشیا را پیدا کند.
cls_loss
این معیار خطای تشخیص کلاس را نشان میدهد.
اگر cls_loss کاهش پیدا کند، یعنی مدل بهتر تشخیص میدهد هر شیء مربوط به کدام کلاس است.
precision
Precision نشان میدهد از بین پیشبینیهایی که مدل انجام داده، چه تعداد درست بودهاند.
اگر precision بالا باشد، یعنی مدل کمتر اشتباه مثبت تولید میکند.
recall
Recall نشان میدهد از بین اشیای واقعی موجود در تصویر، مدل چند مورد را پیدا کرده است.
اگر recall پایین باشد، یعنی مدل بعضی اشیا را پیدا نمیکند.
mAP
mAP یکی از مهمترین معیارها در Object Detection است.
بهصورت ساده، mAP نشان میدهد مدل در تشخیص درست کلاسها و مکان اشیا چقدر خوب عمل کرده است.
رفتار خوب در نمودارهای آموزش
در یک آموزش سالم معمولاً این اتفاقها را میبینیم:
box_lossکاهش پیدا میکند.cls_lossکاهش پیدا میکند.precisionافزایش پیدا میکند.recallافزایش پیدا میکند.mAPافزایش پیدا میکند.اختلاف عملکرد train و val خیلی زیاد نمیشود.
اگر loss کم شود اما mAP بهتر نشود، ممکن است دیتاست یا لیبلها مشکل داشته باشند.
اگر عملکرد train خوب باشد اما val ضعیف بماند، احتمال overfitting وجود دارد.
فایلهای خروجی مربوط به پایش آموزش
بعد از Train، معمولاً فایلهایی شبیه موارد زیر ساخته میشوند:
results.png
results.csv
labels.jpg
confusion_matrix.pngفایل results.png نمودار روند آموزش را نشان میدهد.
فایل results.csv مقادیر عددی هر epoch را ذخیره میکند.
فایل confusion_matrix.png نشان میدهد مدل کدام کلاسها را با هم اشتباه گرفته است.
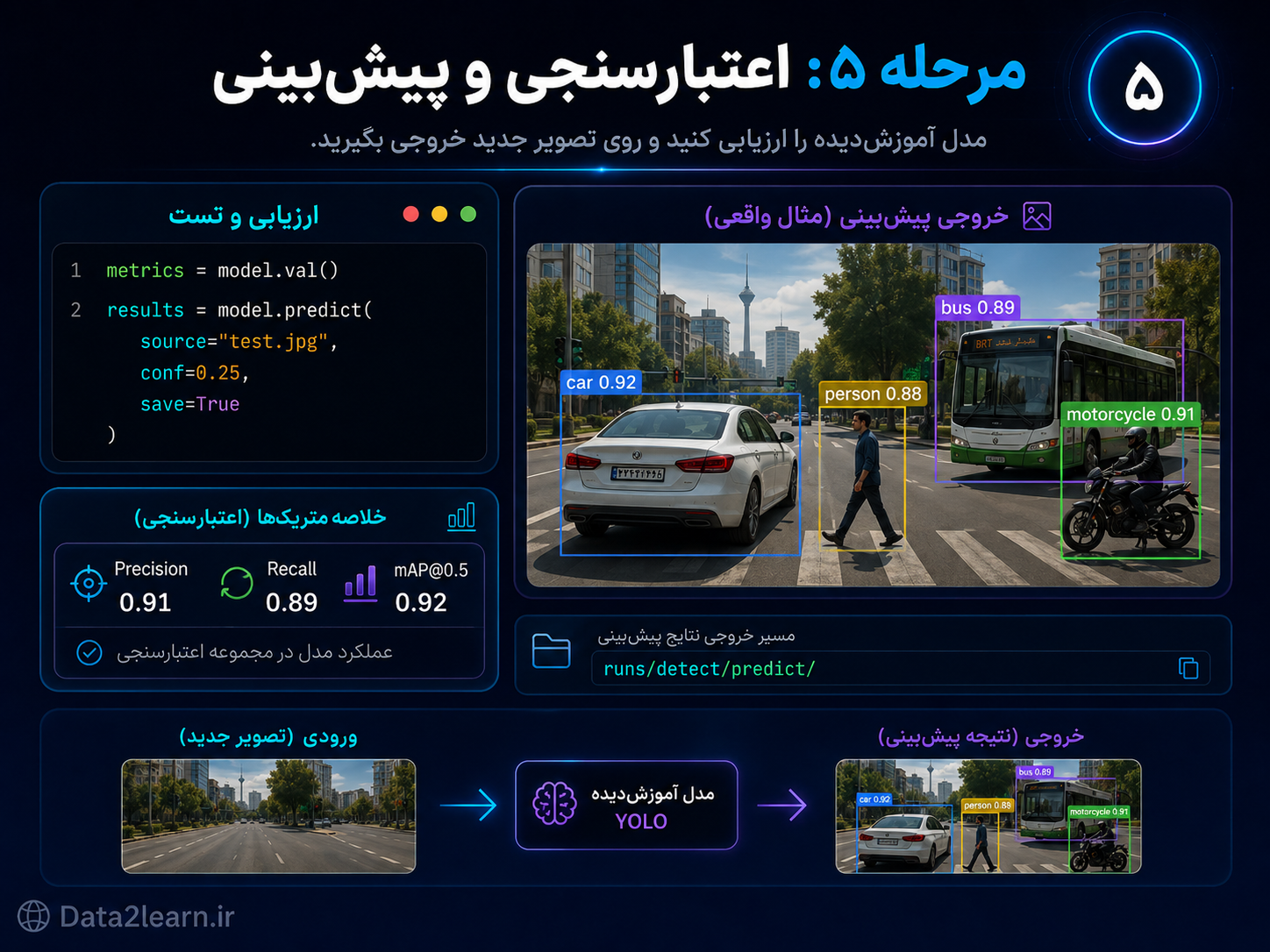
مرحله ۵: اعتبارسنجی و پیشبینی
بعد از پایان Train، باید مدل را ارزیابی کنیم. این ارزیابی مشخص میکند مدل روی دادههایی که برای آموزش ندیده، چقدر خوب عمل میکند.
برای این کار از model.val() استفاده میکنیم.
کد اعتبارسنجی
metrics = model.val()
print(metrics)این دستور مدل را روی مجموعه validation بررسی میکند و معیارهایی مثل precision، recall و mAP را برمیگرداند.
پیشبینی روی تصویر جدید
بعد از ارزیابی، بهتر است مدل را روی یک تصویر جدید هم تست کنیم.
results = model.predict(
source="test.jpg",
conf=0.25,
save=True
)توضیح پارامترها
source
مسیر تصویر یا ویدیوی ورودی است.
source="test.jpg"conf
حداقل میزان اطمینان برای نمایش خروجی است.
conf=0.25اگر این عدد را زیاد کنید، فقط پیشبینیهای مطمئنتر نمایش داده میشوند.
اگر آن را کم کنید، خروجیهای بیشتری نمایش داده میشود، اما احتمال خطا هم بیشتر میشود.
save
اگر مقدار آن True باشد، خروجی ذخیره میشود.
save=Trueمسیر ذخیره خروجی پیشبینی
معمولاً خروجی prediction در مسیری شبیه زیر ذخیره میشود:
runs/detect/predict/در این پوشه میتوانید تصویر خروجی را ببینید؛ همان تصویری که روی آن Bounding Box، نام کلاس و confidence score قرار گرفته است.
چرا دیدن خروجی تصویری مهم است؟
گاهی معیارهای عددی خوب هستند، اما خروجی تصویری نشان میدهد مدل هنوز در بعضی شرایط مشکل دارد.
مثلاً ممکن است:
اشیای کوچک را تشخیص ندهد.
بعضی کلاسها را با هم اشتباه بگیرد.
روی نور کم عملکرد ضعیفی داشته باشد.
Bounding Boxها را دقیق رسم نکند.
فقط روی زاویههای خاص خوب عمل کند.
بنابراین همیشه علاوه بر بررسی عددها، خروجی تصویری مدل را هم نگاه کنید.
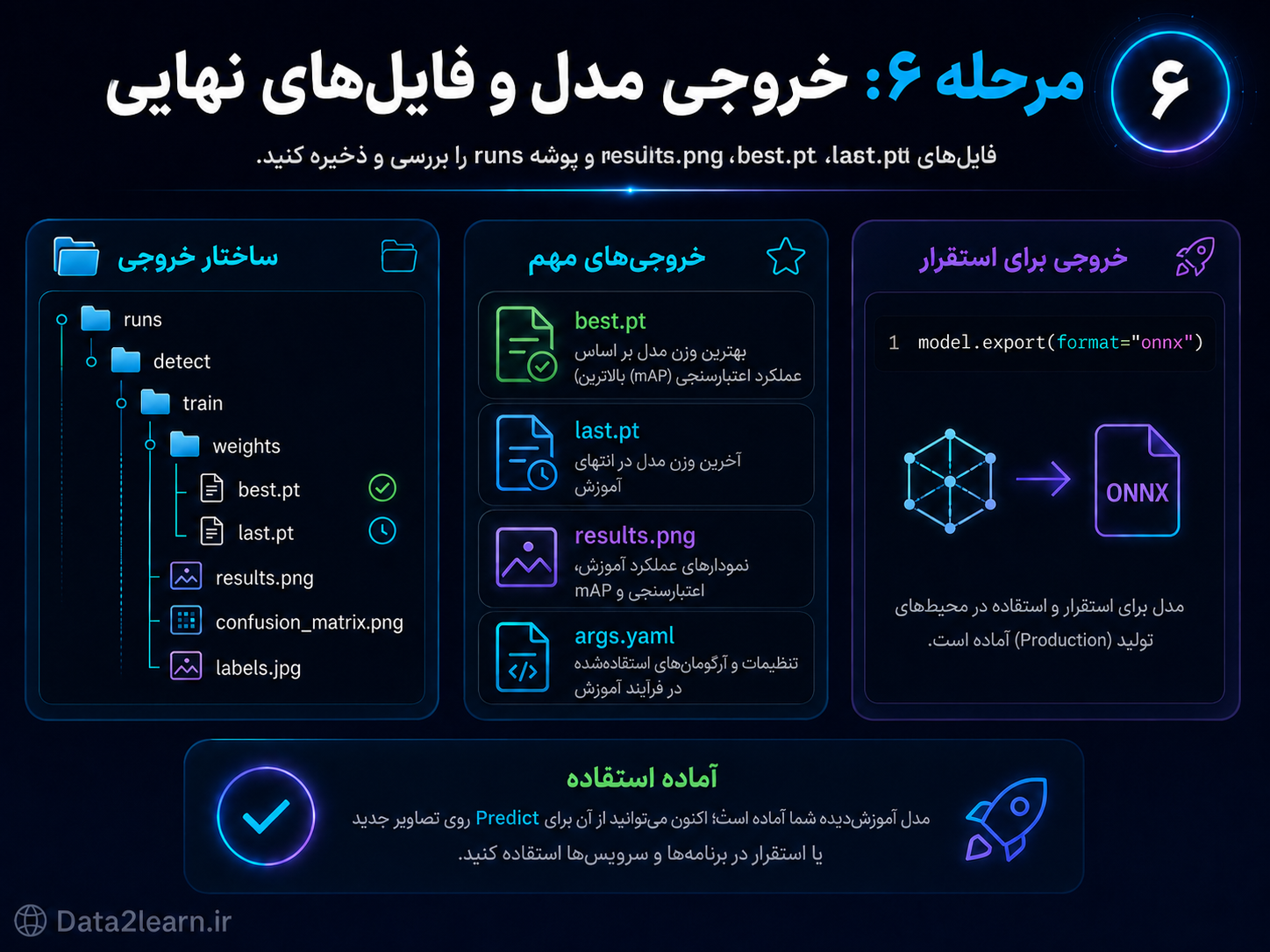
مرحله ۶: خروجی مدل و فایلهای نهایی
بعد از پایان Train، YOLO خروجیهای مختلفی تولید میکند. مهمترین خروجیها معمولاً داخل پوشه runs ذخیره میشوند.
ساختار خروجی ممکن است شبیه این باشد:
runs/
└── detect/
└── train/
├── args.yaml
├── results.png
├── confusion_matrix.png
├── labels.jpg
└── weights/
├── best.pt
└── last.ptفایلهای مهم خروجی
best.pt
این فایل بهترین وزن مدل است. معمولاً بر اساس بهترین عملکرد روی validation ذخیره میشود.
برای استفاده واقعی، بیشتر مواقع همین فایل را استفاده میکنیم.
last.pt
این فایل آخرین وزن مدل در پایان آموزش است.
اگر بخواهید آموزش را ادامه دهید یا آخرین وضعیت مدل را بررسی کنید، این فایل کاربرد دارد.
results.png
نمودارهای روند آموزش داخل این فایل ذخیره میشود.
results.csv
مقادیر عددی هر epoch داخل این فایل قرار میگیرد.
confusion_matrix.png
این فایل نشان میدهد مدل کدام کلاسها را با هم اشتباه گرفته است.
args.yaml
تنظیماتی که هنگام Train استفاده شدهاند داخل این فایل ذخیره میشوند.
استفاده از مدل آموزشدیده
بعد از Train، میتوانید مدل را اینطور بارگذاری کنید:
from ultralytics import YOLO
model = YOLO("runs/detect/train/weights/best.pt")
results = model.predict(
source="test.jpg",
conf=0.25,
save=True
)در پروژه واقعی، معمولاً مسیر best.pt را نگه میداریم و از آن برای تشخیص روی تصاویر جدید استفاده میکنیم.
خروجی گرفتن برای استقرار
اگر بخواهید مدل را در محیط Production یا سرویسهای دیگر استفاده کنید، میتوانید آن را به فرمتهای مختلف export کنید.
مثلاً خروجی ONNX:
model.export(format="onnx")این خروجی برای استفاده در بعضی موتورهای inference، اپلیکیشنها یا سرویسهای مختلف کاربرد دارد.
خطاهای رایج هنگام Train کردن YOLO
۱. مسیر data.yaml اشتباه است
اگر YOLO فایل data.yaml را پیدا نکند یا مسیرهای داخل آن اشتباه باشند، آموزش شروع نمیشود.
۲. نام فایل تصویر و لیبل یکی نیست
برای هر تصویر باید یک فایل لیبل همنام وجود داشته باشد.
مثلاً:
image_001.jpg
image_001.txt۳. شماره کلاسها اشتباه است
اگر در فایل لیبل عدد 0 برای car باشد اما در data.yaml عدد 0 برای person تعریف شده باشد، مدل اشتباه آموزش میبیند.
۴. batch بیش از حد بزرگ است
اگر batch بزرگ باشد و حافظه GPU کافی نباشد، خطای کمبود حافظه میگیرید.
در این حالت مقدار batch را کمتر کنید:
batch=8یا:
batch=4۵. دیتاست تنوع کافی ندارد
اگر تصاویر خیلی شبیه به هم باشند، مدل در شرایط جدید ضعیف عمل میکند.
۶. تعداد epoch خیلی کم است
اگر epoch کم باشد، مدل هنوز فرصت یادگیری کافی پیدا نکرده است.
۷. تعداد epoch خیلی زیاد است
اگر epoch زیاد باشد، مدل ممکن است روی دیتاست train بیش از حد وابسته شود و روی تصاویر جدید عملکرد خوبی نداشته باشد.
۸. لیبلها دقیق نیستند
لیبل اشتباه، کلاس اشتباه یا Bounding Box نامناسب باعث افت شدید دقت مدل میشود.
چکلیست نهایی قبل از Train
قبل از شروع آموزش، این موارد را بررسی کنید:
ساختار پوشهها درست است.
فایل
data.yamlدرست نوشته شده است.مسیرهای
trainوvalوجود دارند.برای هر تصویر، فایل txt همنام وجود دارد.
شماره کلاسها با
namesهماهنگ هستند.تصاویر تکراری زیاد حذف شدهاند.
لیبلها بررسی شدهاند.
batch با حافظه GPU سازگار است.
مدل پایه مناسب انتخاب شده است.
جمعبندی
برای Train کردن مدل YOLO با دیتاست اختصاصی، باید چند مرحله را بهدرستی انجام دهید. ابتدا محیط را آماده میکنید، سپس فایل data.yaml را میسازید، مدل پایه را انتخاب میکنید و آموزش را با Python یا CLI اجرا میکنید.
بعد از شروع آموزش، باید معیارهایی مثل loss، precision، recall و mAP را بررسی کنید. در پایان نیز خروجیهایی مثل best.pt، last.pt، results.png و confusion_matrix.png را ذخیره و تحلیل میکنید.
اگر این مراحل درست انجام شوند، میتوانید یک مدل YOLO اختصاصی بسازید که برای پروژه واقعی شما قابل استفاده باشد.
دیدگاههای مقاله
۰ دیدگاه تایید شدههنوز دیدگاهی ثبت نشده است
اولین نظر یا سوالت درباره این مقاله را بنویس.